【テクニカルレポート】ビッグデータに対するテキストマイニング技術とその適用例……ユニシス技報
エンタープライズ
ソフトウェア・サービス




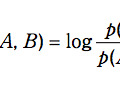

ソーシャルメディアや企業内の情報システムに蓄積されている大規模かつ更新頻度の高いテキストデータは“ビッグデータ”の代表例とされる.本稿では,企業活動において有益な知見をテキストデータから得るためのテキストマイニング技術の基礎,日本ユニシス独自の手法である“話題の変化を把握する技術”と“話題を可視化する技術”をその適用例とともに紹介する.ビッグデータの分析ではさまざまな情報を掛け合わせることでより大きな価値を生むとされるが,これらの手法は商品の売上や株価などの定量データとテキストデータを組み合わせて分析する際にも活用できる.
1.はじめに
2011 年ごろから“ビッグデータ”を解析して企業活動に利用する取り組みが盛んになっている.ビッグデータとは Volume(規模の大きさ),Variety(多様な形式),Velocity(高い発生頻度)の特性から,従来の技術では管理・分析が難しいデータのことである.企業の情報システムには販売や接客などで発生するさまざまなデータが蓄積されている上,スマートデバイスやセンサーを備えた情報機器の普及が進んだことから大量のデータが手に入るようになり,その分析ニーズが高まっている.データマイニングや機械学習などの分析技術,高性能ハードウェアや並列分散処理などの基盤技術の進化により,分析のための土壌は整いつつある.
ビッグデータの対象となるデータには売上や株価といった定量情報のほか,テキスト,画像,動画,センサー,GPS,音声などが存在する.TwitterやFacebook,クチコミサイト,ブログといったソーシャルメディア上の書き込みはテキストデータとして蓄積され,ビッグデータの代表例として取り上げられる.本稿では,2章にて企業活動におけるテキストデータの用途,3章にてその分析技術について記述し,4章では日本ユニシスの取り組みを紹介する.5 章は事例である.
ビッグデータの分析ではさまざまな情報を組み合わせることでより大きな価値を生むことができると考えられている.定量データの分析にテキストデータを組み合わせる技術についても併せて紹介する.
2.企業活動に有益なテキストデータ
企業内外にはさまざまなテキストデータが存在する.本章では企業活動に有益なテキストデータとその用途を記述する.
2. 1 テキストデータの種類と用途
企業活動に利用できるテキストデータには表1のようなものがある.
ソーシャルメディアでは,自社商品や競合商品に対する意見や企業イメージ,CMへの反響,製品についての苦情がありのままに語られることから,表2のような場面で活用できる.
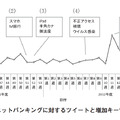
TwitterやSNSでの発言は実世界をリアルタイムに映し出すため,社会環境の調査にも利用できる.例えばTwitter上で「風邪」を含むつぶやきを検索し,付随するGPS情報と合わせてその時間的な動きを見れば,風邪の時間的・空間的な広がりを観測できる可能性がある.議員選挙の当落予想や災害時の不足物資を推測する試みも行われている.
ソーシャルメディアが注目される一方で,従来から分析対象とされてきた企業内の情報も活用されている.コールセンターではソーシャルメディアと異なり,双方向のコミュニケーションが顧客との間で行われる.コールセンターの情報は,商品の不具合や顧客の要望を詳細に知ることができるため,品質管理や商品改善に欠かせない.また商品アンケートでは企業側が知りたい意見をピンポイントで収集することができる.意見の収集にソーシャルメディアを使うことで費用削減を図れるが,ソーシャルメディアでは語られにくい話題も存在する.必要に応じてアンケートを併用し,意見収集することが有効と考える.
ソーシャルメディア・企業内に関わらず,各々の媒体では発言者の属性や発言の目的が少しずつ異なる.分析時にはこうした点を考慮に入れて結果を解釈する必要がある.
2. 2 定量データとの組み合わせによる効果
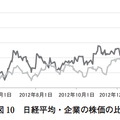
株価や売上,CS(顧客満足度)などは企業経営を大きく左右する重要な指標である.その好調・不調の原因を探るための参考情報として,ソーシャルメディアやコールセンターなどのテキストデータを役立てることができる.例えば,商品の売上や企業の株価が落ち込んだ際,その直前で商品や企業に対して悪評が広まっていれば,それに起因しているという仮説を立てられる.以後,ネガティブな話題の増加を早期に検知して原因を探ることができれば,信用失墜や賠償に伴う損害が大きくなる前に対策を立てることができる.
3.テキストマイニング技術の基礎
テキストマイニングとは大量のテキストデータの中から価値のある知見を得る技術のことである.本章ではテキストマイニング技術の基礎について記述する.
テキストデータは定量データとは異なり文字列であるため,そのままでは扱いづらい“非構造化データ”である.構文を解析して単語や係り受けを抽出するか,内容に応じた分類付けをしないと集計や分析に利用できない.一般にテキストからの単語抽出は“形態素解析”,係り受け抽出は“係り受け解析”という技術によって行われる.
3. 1 形態素解析とセンチメント分析
テキストデータに含まれる文を単語に分割し,その品詞を特定することを形態素解析と呼ぶ.日本文は,英文のように文中の単語が空白で区切られていないため,他国語より難解である.そのため,より精度を高めようと盛んに研究が行われてきた.主流となっているのは,大量の文を人手で単語に分割した正答データ(コーパス)を用いて,各単語の出現のしやすさ,品詞同士の隣り合いやすさをスコア化して“辞書”として保持し,解析時に利用する手法である.この辞書には単語のバリエーションがスコアと共に保持される.
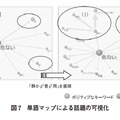
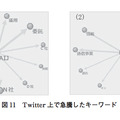
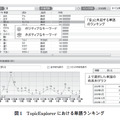
多くのテキストマイニングツールでは,文に含まれる単語のランキングを表示して全体を概観する.この時,図1のように各単語がポジティブまたはネガティブな意味を持つのかを示し,内容をつかみやすくするツールも存在する.各単語のポジティブ・ネガティブの判定は“センチメント分析”と呼ばれ,文中の単語の共起関係を利用する方法,類義語や同義語の語彙集(シソーラス)を利用する方法などで行われる[1].本稿では前者について解説する.前者ではポジティブあるいはネガティブの典型的な語をあらかじめ用意しておいて,どちらの語と共起しやすいかに基づき単語を選別する.共起の尺度としては以下のPMI(Pointwise Mutual Information)[2][3]がよく用いられる(画像参照).式の p(A)は単語Aが出現する確率,p(B) は単語Bが出現する確率,p(A, B) は単語AとBが共に出現する確率である.
ある単語のポジティブ・ネガティブの判定はそれぞれの典型的な語とのPMIを求めて,その値が大きい方とするなどの方法で行う.この時,両者のPMIに大きな差がない単語はどちらでもないと判定する.
3. 2 係り受け解析
主語‒述語,修飾語‒被修飾語など文節間の依存関係のことを係り受けと呼ぶ.文から係り受けを抽出する手順は以下のとおりである.
Step1. 形態素解析によって文を単語に分割する
Step2. 隣接する単語の前後で文節の切れ目を判定する
Step3. 文節を二つずつ取り上げ,係り受け関係の有無を判定する
文節の判定,文節間の係り受けの判定には SVM(Support Vector Machine)を用いて行う方法がある[2][4].SVMには手作業で作成した文節や係り受けの正答データを学習させており,そこから導き出された規則を用いて,結果を推定する.
テキストマイニングツールでは単語と同様に係り受けをランキングとして表示し,全体を概観する.また,図1の単語ランキングにおいて単語だけでは内容の解釈が難しい場合に,その単語を含む係り受けの一覧を図2のように表示することで利用者の理解を助ける.
3. 3 文書分類
テキストデータに対して自動で内容に応じた分類付けをすることを“文書分類”と呼ぶ.企業のコールセンターではデータ登録時に人手で分類が付与されることがある.しかし,ほとんどのソーシャルメディアでは書き込み時に分類は付与されない.集計・分析時に人手で対応することもできるが,対象が数万件に及ぶ場合,困難である.そこで文書分類の技術が必要とされる.文書分類には,既に分類付けしてあるデータを用い自動で付与ルールを作成する方法と,人が知識や直感によって付与ルールを作成する方法がある.文書分類の身近な応用例として電子メールソフトの自動仕分け機能がある.電子メールソフトでは,件名や本文に含まれる文字でメールを特定のメールフォルダーに仕分けするルールを登録することができる.また,スパムフィルタは不要なメールを自動で判別してくれる.このスパムフィルタは一般にナイーブベイズ分類器[2]を用いており,人がスパムと判定した過去メールを学習している.
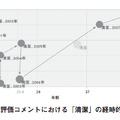
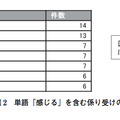
図3のように分類ごとの件数を集計することで話題の構成比を把握できる.単語のランキングと比べ,業務に沿った視点で情報を整理することができるため,企業の管理層に対するレポートに向いている.しかし分類体系の整備や付与ルールの作成といった準備に多くの時間が掛かる.またソーシャルメディアのように新たな話題が次々と挙がってくる媒体では,分類を継続的に見直す必要があるため,維持が難しく不向きである.
※同記事は、日本ユニシスの発行する「ユニシス技報」2013年3月発刊 Vol.32 No.4 通巻115号からの転載記事である。