【テクニカルレポート】検索技術による企業内外データの仮想統合(前編)……ユニシス技報
エンタープライズ
ソフトウェア・サービス






検索技術により、企業内外に散在するデータを仮想的に統合する「情報アクセス基盤」と、その上でデータを分析・活用するアプリケーション(Search Based Application:SBA)が注目を集めはじめている。SBAは意思決定や、マーケティング、リコールの予兆の検知等、複雑な要求に応えるアプリケーションである。
本論文では、オープンソースの検索エンジンであるApache Solrをはじめとした複数のOSSを活用して情報アクセス基盤を構築する意義と、構築にあたっての留意点を、SBAの構築事例を踏まえて報告する。
1.はじめに
IT 環境の進化によって、企業内に蓄積されるデータ量は爆発的に増大し続けている。それらの膨大なデータは、各種業務システムやグループウェア、ファイルサーバー等、企業内の各部門単位で存在しており、その中から必要な情報を即座に探し出すことは非常に困難である。一方で、急速に拡大しているソーシャルメディアや口コミ情報等のデータの中から有益な情報を抽出し、より良い意思決定に利用したいというニーズが高まっている。そのような課題とニーズに対し、検索技術により、企業内外の構造化・非構造化データを仮想的に統合することで情報アクセス基盤を構築し、その上にデータを分析・活用するアプリケーション(Search Based Application:SBA)を構築することが、解決策の一つとなる。
本論文では,オープンソースの検索エンジンであるApache Solr をはじめとした複数の
OSS を活用して情報アクセス基盤を構築する意義と、構築にあたっての留意点を、SBAの構築事例を踏まえて報告する。
2.検索技術による企業内外に散在するデータの仮想統合
本章では、企業内外に散在するデータを対象とした検索技術による情報アクセス基盤の構築の意義と、その位置づけについて記述する。
2.1 インターネット検索とエンタープライズサーチ
インターネット検索は1994年にはじまったとされており、インターネット検索エンジンの最大手であるGoogleの創業は1998年である。その技術を企業内で利用するための検索製品は2000 年頃から徐々に登場し、本格的に活用されはじめたのは2005年頃からである。この企業内外のWebサイトを含め、企業内の業務システムやファイルサーバー等に格納されている情報を横断的に検索するコンセプトを「エンタープライズサーチ」という。
インターネット検索は従来、インターネット上のWebページをはじめとした文書内の文章の検索に用いられてきたが、エンタープライズサーチではインターネット上の文書だけでなく業務システムのデータベース内の情報も対象になることが大きな特徴と言える。
2.2 情報アクセス基盤によるデータの仮想統合
検索技術は情報を見つけ出す手段であるとともに、企業内外に散在する構造化データおよび非構造化データを、仮想的に統合し処理する基盤技術として利用されている。このような技術を基に、意思決定や、マーケティング、リコールの予兆の検知等、複雑な要求に応えるアプリケーションを、Search Based Application(以下、SBAと記述する)と呼び、それを可能とする基盤を「情報アクセス基盤」と呼ぶ。
2.3 検索技術による情報アクセス基盤の位置づけ
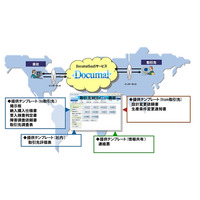
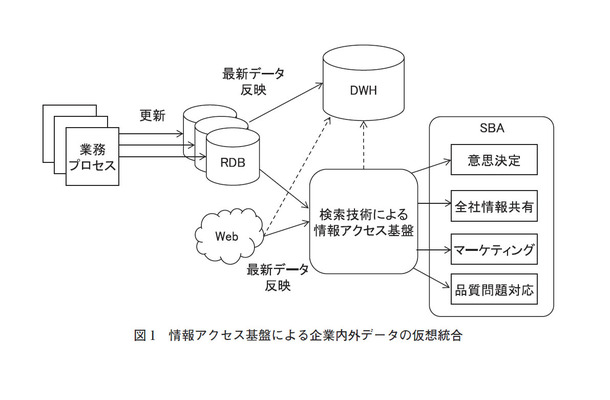
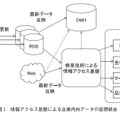
検索技術による情報アクセス基盤は、従来のリレーショナルデータベース(以下、RDBと記述する)の役割の代替とはならず、共存する関係となる。RDBは企業の基幹データを扱うトランザクション処理を担い、検索技術ではRDBのスナップショットを定期的に取得しデータを効率よく参照するための機能を提供する。RDBでも全文検索は可能だが、パフォーマンスが問題となる場合がある。またRDBは集合であるため、値によるソート順での表示となるが、検索技術では、表記ゆれへの対策や「スコア」によるランキングが行われるため、よりユーザニーズに合致したデータを、合致した度合いで提示することができる。
データの統合と分析は、従来、データウェアハウス(DWH)が役割を担っており、高度な分析に使用される。検索技術による統計や分析は簡易的なものとなるが、比較的低コストでの導入が可能なため、データ活用のエントリーポイントとして考えることができる。
図1に、企業における検索技術を含めたシステム構成の例を示す。
3.情報アクセス基盤を実現する検索技術の仕組み
本章ではオープンソースの全文検索エンジンサーバーであるApache Solrを例として、SBAの情報アクセス基盤となる検索技術の仕組みについて解説する。
3.1 全文検索とは
全文検索とは、複数のドキュメント(文書ファイル・DB・Webページなどの個々のテキストデータ)にまたがって、ドキュメントに含まれる全文を対象として検索するという意味である。全文検索の方式には大きく分けて順次検索(grep)方式とインデックス方式があるが、ほとんどの全文検索エンジンは高速な検索が可能となるインデックス方式を採用している。また、インデックスのデータ構造にはいくつか種類があるが、パフォーマンスの面で優れる「転置インデックス」(※1)が一般的に使用されている。
3.2 全文検索の仕組み
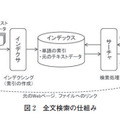
全文検索は、事前準備としてクロール・インデクシングという処理が必要であり、検索実行時は、検索画面から入力された検索式をサーチャが解析し、事前作成していたインデックスを検索することにより、検索結果を利用者に返す(図2)。
クローラにより、検索対象とするドキュメント(ファイル・DB・Webページなど)を収集し(クロール)、インデクサにより、収集したドキュメントを検索するための索引(インデックス)を作成する(インデクシング)。
3.3 OSS 全文検索エンジンApache Solr
Apache Solr(※2)(アパッチ ソーラー。以下、Solrと記述する)はオープンソースの全文検索エンジンサーバー(※3)の一つである。Solrは、コミュニティーの活発さ(数千人の開発者)、更新頻度(ほぼ毎日)、ダウンロード数(1日 6000回~10000回)から見て、2012年現在、オープンソースでは最有力の検索エンジンと言える。Solrは必要十分な機能と高いスケーラビリティを持ち、Twitter社等Web系企業を中心に超大規模事例が爆発的に増えており、国内でも適用事例が増加し続けている。また、動的な絞り込み検索(ファセット機能)等の検索機能やインデクシングにカスタマイズ処理を追加できる仕組みを持ち、商用製品と比べても機能的に優位性があると言える。
Solrの最も大きな特徴はオープンソースソフトウェア(以下、OSS)であることである。一般的にOSSは、リリース管理、サポート等の課題があると言われているが、IDC、ガートナーによるとほぼ半数以上の企業でOSSが導入されており[5]、震災等の影響から更にOSSの採用率が加速するとの分析結果がある[6]。商用の検索製品はサーバー台数やデータ量によってライセンス費用が非常に高額になるものが多いため、特に大規模なデータ処理を必要とする案件ではOSSの使用によるコストメリットが大きい。
3.4 情報アクセス基盤を実現するために必要な機能
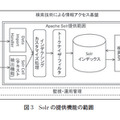
SBAの情報アクセス基盤を検索技術で実現するために必要な機能は、Solrを中心とした複数のOSSを活用して提供することができる。図3に、情報アクセス基盤におけるSolrの提供機能の範囲を示す。クローラや管理機能は他のOSSを組み合わせて構築する。グループウェア等のクロールには、商用のクローラや作り込みが必要となる場合がある。SBAの構築には、OSSのWebアプリケーションフレームワークがSolr向けに用意されており、またSolrをコアとして利用可能な商品も存在するため、用途に合わせて構築方法を検討する。
3.4.1 データベースクロール
情報アクセス基盤として、データベース内のデータを収集して仮想的に統合するためには、データベースの複数のテーブルを関連付けた状態で取得し、インデクシングする機能が必要である。SolrではDataImportHandler(DIH)というツールが標準で提供されている。DIHはRDBやXML、ファイル等のデータソースから検索対象となるデータを取り出し、Solrに登録するツールである。DIHで取得したデータは項目ごとに、正規表現による文字列の置換や、日付、数値のフォーマット変換等を指定できる。
3.4.2 トークナイザとフィルタ
検索エンジンのインデックスを作成するには、文章を単語に分割するトークナイザと、表記ゆれへの対策や名寄せ等を行うフィルタを使用する。トークナイザとフィルタは情報アクセス基盤におけるデータクレンジング(※4)の機能の一部を担うものである。
Solrではインデックスに格納する各データ項目に対し、トークナイザと複数のフィルタを組み合わせて設定することができる。以下に主なトークナイザおよびフィルタを示す。
・トークナイザ:日本語等のスペース区切りでない文章を単語に分割するためには、形態素解析方式またはN-Gram方式のトークナイザを使用する。それぞれの特徴は表1のとおりである。
・フィルタ:フィルタは文字を置換する文字フィルタと、トークナイザによる単語分割後に処理をするトークンフィルタの2種類があり、それぞれの特徴は表2のとおりである。トークンフィルタの一部はトークナイザが形態素解析である必要がある。
3.4.3 インデクシングへのカスタマイズ処理の追加
フィルタによる表記ゆれへの対策や、名寄せでは対応できないマスターテーブルの参照、プログラムによるデータの変換や補完が必要となる場合、Solrではインデクシングにカスタマイズ処理を追加して対応することができる。例として、以下のようなものがある。
・ファイルパスから独自のルールでタグや分類を付加する
・口コミの文章から特徴語を抽出して属性として付加する
・テキストマイニング技術で対象データに自動的にカテゴリを設定する
3.4.4 ダイナミックドリルダウン
インデクシングされたデータを検索する機能として、キーワードによる検索以外で重要なのがダイナミックドリルダウンと呼ばれる機能であり、Solrでは「ファセット機能」として提供されている(図4)。ダイナミックドリルダウンは、検索結果全体をカテゴリや日付などで絞り込み、利用者をナビゲートする仕組みであり、オンラインストア等の検索機能において必須の機能となりつつある。また、この機能は検索結果の中から指定した属性を持つ件数を項目ごとに把握できるため、SBAでは分析・統計の目的に使用される。
■注釈
*1:転置インデックスとは、全文検索を高速に行うことを目的とした、単語をキーとしその単語を含むドキュメントのIDのリストからなるテーブルのことである。
*2:Apache SolrはApache Lucene(Javaを基盤とした検索ライブラリー)上に構築されたウェブ・サービス層である。Luceneを直接利用するには情報検索分野での経験および大掛かりなプログラム構築が必要となるが、Solrを利用することでコードを最初から作成するコストとリスクなしで、拡張性の高い検索機能が得られる。
*3:Apache SolrはHTTPを介して呼び出し可能なREST類似のウェブ・サービス・インターフェースを持ち、XMLベースの構成ファイルを使用することで機能の設定が可能。Javaをはじめとし、C#、Perl、Ruby等のAPIも備える。
*4:データクレンジングとは、データの統計をとる目的で、データ形式の統一や、欠損値の補完、データの正規化等を行うことである。
■参考文献
[1]Gregory Grefenstette and Laura Wilber, “Search-Based Applications - At the Confluence of Search and Database Technologies”, Morgan & Claypool Publishers, 2011
[2]Leslie Owens, “Tapping The Power Of Search-Based Applications”, Morgan & Claypool Publishers, March 2011
[3]清兼義弘.関口宏司.田澤孝之.松野良蔵,「エンタープライズサーチ 技術と導入」,アスキー・メディアワークス,2008年9月
[4]吉川日出行,「サーチアーキテクチャ「さがす」の情報科学」,みずほ情報総研株式会社,ソフトバンククリエイティブ,2007年10月
[5]Laurie F. Wurster, Bob Igou, Zeynep Babat, “Survey Analysis: Overview of Preferencesand Practices in the Adoption and Usage of Open-Source Software”, Gartner,Inc., January 2011
[6]「国内ソフトウェア市場予測を発表」,IDC Japan 株式会社,2011年5月24日,http://www.idcjapan.co.jp/Press/Current/20110524Apr.html
[7]「2010年度オープンソースソフトウェア活用動向調査」,The Linux Foundation Japan,2011年7月,http://www.linuxfoundation.jp/jp_uploads/SI_Forum_OSS_Survey_2010.pdf
[8]Aaron Wall, “History of Search Engines: From 1945 to Google Today”,http://www.searchenginehistory.com/
※参考文献[6]~[8]に含まれるURL は,2012年2月時点での存在を確認
■執筆者紹介(敬称略)
石井 愛(Ai Ishii):2003年日本ユニシス(株)入社、オープンミドルウェア製品主管部にて保守・開発に従事。2009年より総合技術研究所に移籍し、検索技術領域の評価と研究を主体とした活動をする。
※同記事は、日本ユニシスの発行する「ユニシス技報」2012年3月発刊 Vol.31 No.4 通巻111号からの転載記事である。