【テクニカルレポート】ビッグデータに対するテキストマイニング技術とその適用例……ユニシス技報
エンタープライズ
ソフトウェア・サービス




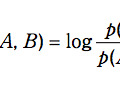

4.日本ユニシスのテキストマイニング技術
日本ユニシスでは1997年以降,テキストマイニングの製品開発およびその適用を行ってきた.本章ではその中で培ってきた,テキストデータで語られている話題の変化を把握する技術,話題の内容を可視化する技術について記述する.ともにビッグデータの特性であるVolume(規模の大きさ),Velocity(高い更新頻度)に対応した独自アプローチを採っている.
4. 1 話題の変化を把握する技術
テキストデータで語られている話題の経時的な変化を把握する手法について紹介する.ここで“話題の変化”とはさまざまな話題の出現件数の増減を指している.
クチコミサイトにおける話題の増減から消費者トレンドの変化を早期に捉えることができれば,他社に先駆けてニーズにあった商品を提供し,大きな収益をあげることができる.また話題の増減は新商品の発売やTV番組・CMによる情報発信,製品不具合の発生などに起因することが多いため,2. 2節で述べた定量データと組み合わせた分析の際に有効な情報となる.
4. 1. 1 話題の変化を把握するには
話題の変化を捉える一般的な方法は,単語や係り受けの出現件数を時間ごとに集計してその推移を確認することである.例えば,特定の時期に「危ない」「故障」などの単語が突発的に増えていれば,製品欠陥に関わる話題が急騰していると推測できる.
この方法では,着目すべき単語や係り受けが決まっていれば,人手で傾向を捉えることができる.しかし分析テーマに合わせて単語や係り受けを適切に選ぶにはノウハウが必要な上,大きな手間が掛かる.また,選んだ単語や係り受けに漏れがある場合,重大な事象を見落としかねない.そこですべての単語や係り受けを対象にして自動的に変化を捉え,通知してくれる仕組みが必要となる.
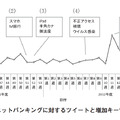
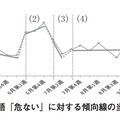
図4は,ある自動車のクチコミデータにおける単語「危ない」の出現件数を表した時系列グラフである.これに対して複数の直線からなる傾向線を当てはめる.
図中(1)~(4)のような直線同士のつなぎ目を分割点と呼び,各直線の傾きや分割点で隣りあう直線の関係を分析することで,以下のような特徴を把握する.
[急増] 特定の期からその次期で急に増加する
[増加傾向] 特定の期から数期に渡って継続的に増加する
[減少傾向] 特定の期から数期に渡って継続的に減少する
[急減] 特定の期からその次期で急に減少する
この処理をすべての単語に適用する.見つけた増加傾向または減少傾向は,直線の傾きから1期あたりの伸び数や伸び率を求める.同様に,急増点や急減点についても前期からの伸び数や伸び率を求める.伸び数や伸び率を手がかりとして,変化の大きい単語に着目すれば,話題の変化を類推できる.
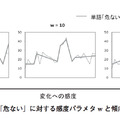
なお,傾向線を当てはめる際には,変化への“感度”を調整するパラメタ w(正の整数)をあたえる.パラメタ w は図5のように大きな値にするほど変化の捉え方がおおまかになる.
一概に話題の変化を捉えるといっても,利用者は大まかな傾向だけを捉えたい場合もあれば,細かい増減まで知りたい場合もある.例えば,図4の(4)の右側では,全体を平坦とする見方もあれば,8月第3週の付近で減少しているという見方もある.こういった小さな変化への“感度”をパラメタ w によって調整できる.
4. 1. 2 話題の変化を把握する具体的な手法
4. 1. 1項で示した機能を実現する具体的な手法について詳細を記述する.
1) 傾向線の当てはめ方法
図6を使って,ある単語の出現件数を表したグラフに傾向線を当てはめる方法を示す.この方法では図中のStep1,Step2の手順で傾向線を作り上げる.
Step1)
まず,時間軸(横軸)の左端を始点として w 期の点を取り上げ,この中で直線の分割点を探すことを考える.そのため,取り上げた点を前から順に着目し,その前後で回帰直線を引いてみる.すべてのパターンが網羅できたらそれぞれ“情報量規準”を計算し,その値が最も小さい点を分割点とする.ただし,w 期を1本の回帰直線で引いた場合より情報量規準が大きい場合には分割点を設けない.情報量規準とは統計モデルの当てはまりの良さを評価する指標である.この値を用いることで,出現件数と傾向線との誤差を抑えつつ,直線の分割が多くなりすぎないように調整することができる.情報量規準には赤池情報量規準(AIC)などを採用できる[5].
Step2)
次に,直前に分割点とした点から w 期の点を取り上げ,Step1と同様に分割点を探す.もし直前に分割点を設けなかった場合には前回の始点の次期を始点とする.以降,始点がデータの末尾になるまで繰り返す.分割点が決まったら,その前後で回帰直線を分けて引くことにより傾向線を作り上げる.
時間軸の点がt個あるとすると,直線や曲線の分割パターンは 2t通りとなる.期間が長くtの大きいデータでは,すべてを網羅して比較するには膨大な計算が必要となる.それに対して本手法は,組み合わせを効率よく絞ることによって,計算時間をtに比例するように軽減し,指数的な増加を防いでいる.
2) 新たなデータの追加に伴うアウトプットの更新
新たなデータが頻繁に追加される場合には以前のアウトプットを効果的に利用し,計算量を抑制する必要がある.1)で述べた通り,傾向線の分割点は,まずは時間軸の左端から w期の点を取り上げ,次第に対象を右に移して探索する.新しいデータが追加されると右端に点が加わるが,分割点を探索した結果は,直近w期より前の期間では変わらないため,それを再利用できる.データ追加時には,直近w期より前の分割点の中で最も右側にあるものを始点とし,w期の点を取り上げるところから始める.後は同じように対象を右に移しながら分割点を探していく.
3) 複数の感度パラメタ w の指定による精度の向上
4. 1. 1項で述べた感度を調整するパラメタ w は一度に複数あたえることができる.感度パラメタが複数の場合,まず,各値を使って,1)の方法により傾向線を当てはめる.次に,それぞれ情報量規準を計算,最も小さいものを最適な傾向線として,急増・急減などの特徴を判別する.感度パラメタ w を複数あたえることで,多くの傾向線の当てはめ方を候補に入れることができる.そのため,より納得性のある結果を得ることができる.一方で,計算量はあたえる w の数に比例するため,所要時間は増加する.納得性と所要時間のバランス調整が必要となる.
4. 2 話題を可視化する技術
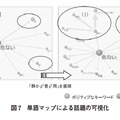
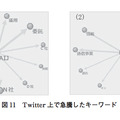
4. 1節の手法を適用すれば,特定の単語の増加を検知することができる.次に利用者はその単語が文脈の中でどのように使われているかを知り,変化している事象を把握する.これは本節で紹介する“単語マップ”によって実現することができる.単語マップは図1に示した単語ランキングにおいて,特定の単語について語られている内容を把握する場合にも利用できる.
4. 2. 1 単語マップとは
図4に例示した「危ない」という単語が急増した6月第2週に着目して,単語マップを描くと図7のようになる.
図7の左側のように,このマップ上では着目した単語「危ない」の周辺にその単語と関連するキーワードを表示する.各キーワードからは,図7の右側の(1)~(3)のように,さらにキーワードを展開させることができる.例えば,(1)では「危ない」と「静か」の両方と関連するキーワードを展開している.この機能により,話題を掘り下げて把握することが可能となる.
図中(1)(2)からは「エンジン音がしないため歩行者は危ない」という話題が,(3)からは「雨の日は危ないので安全運転する」という話題が類推できる.最終的に(1)では,「危ない」と「静か」がともに出現する原文を参照することで類推の正しさを裏付ける.
4. 2. 2 単語マップの実現方法
4. 2. 1項で示した手法について,その実現方法を記述する.
1) キーワードの選別
助詞や助動詞などは“機能語”と呼ばれる[6].機能語は文法的機能を目的とする語のことで,単独では意味を持たない.そのためマップ上ではすべて除外する.一方,名詞や動詞の中にも「もの」「こと」「する」など,どの文にも現れ,文意の把握に役立たない一般語が存在する.これらの単語もマップ上に表示しても不要な情報となるため除外する.
2) キーワードの効率的な探索
ある単語の周辺に表示するキーワードは,その単語と共に出現する頻度の高いキーワードとする.キーワードを何回も展開している場合は,展開元を最上位まで遡って,すべての単語と共起する頻度の高いキーワードを表示する.例えば図7(2)の「エンジン」を展開する場合には「エンジン」だけではなく「音」「危ない」が対象となる.
展開するキーワードには出現頻度による足切りを設けることで,ボリュームのあるテキストデータに対して効率的な探索を実現している.これについて詳述する.
キーワードAが出現するテキストの集合を {A} と表記する.また,キーワードAとキーワードBが共に出現するテキストの集合を {A} ∩ {B} と表記する.この時,キーワードK1から展開したキーワードK2を展開する場合には {K1} ∩ {K2} ∩ {X} の件数 ≧(足切りの出現頻度)を満たすキーワードXを探せばよい.ここで{K1}∩{K2}∩{X}は{K1}∩{X}の部分集合であるため,{K1} ∩ {X} の件数 ≧(足切りの出現頻度)も必ず成立する.この式はキーワードK1を展開した時の条件式なので,キーワードXはK1の展開時にも必ず対象となっている.
以上を一般化して考えると,あるキーワードを展開する場合は,その展開元のキーワードで対象となったキーワードのみを対象として調べればよいことが分かる.なお,図7では1キーワードから展開するキーワードの数を最大10件に絞っているため,(1)~(3)のすべてのキーワードが,展開元である「危ない」の周辺に表示されているわけではない.表示を絞っているのは,利用者が一目で内容を把握できるように重要な情報に限定するためである.
※同記事は、日本ユニシスの発行する「ユニシス技報」2013年3月発刊 Vol.32 No.4 通巻115号からの転載記事である。