KDDI研、有害ページを効率的に自動収集するWebクローラを開発
エンタープライズ
セキュリティ


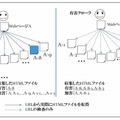
出会い系、あるいは犯罪予告などを目的とした有害ページなどを列記する「ブラックリスト方式」の有害情報フィルタが現在活用されているが、リストを生成するには、有害ページを大量に収集し、内容をチェックする必要があった。そのため、多くのWebページは無害であるため、有害である可能性が高いWebページを効率的に収集できる高度な「Webクローラ」(Webページを自動的に収集するロボットプログラム)が求められていた。
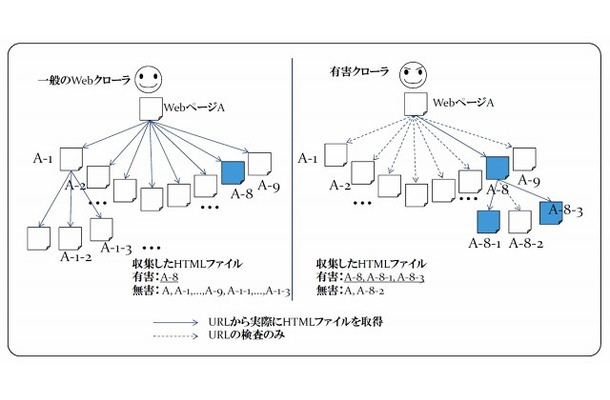
KDDI研究所が開発した「有害クローラ」は、URLから得られるWebページのさまざまな特性を抽出し、Webページ自体を収集する前に有害ページである可能性を推定する点が特長となっている。有害ページに現れやすい特性として、たとえば「安価なサーバを利用している(IPアドレスを他のWebページと共有している)」「有害情報規制の緩い場所にサーバを設置している(他の有害ページとIPアドレスが近い)」といった点を考慮し、従来のWebクローラよりも、有害ページをより多く含めることを可能とした。
実際に、20%の有害ページを含む10,000ページを対象とし、このうち2,000ページを収集する条件で有害ページの収集効率を計測する実験を行ったところ、従来のWebクローラの場合では、2000ページのうちの400ページ(全有害ページの20%)が有害ページであったのに対し、今回開発した「有害クローラ」ではその3.5倍以上となる1430ページ(全有害ページの71.5%)の有害ページが収集可能だった。
KDDI研では今後、ブラックリストを作成しているフィルタリング事業者等に対して本技術の導入を進めるため、開発した有害クローラの大規模な実験を行い、技術開発を進めて行くとともに早期の実用化を目指すとしている。
関連リンク
関連ニュース
-
 NTTドコモ、未成年向けアクセス制限機能を拡充
NTTドコモ、未成年向けアクセス制限機能を拡充
-
 日本動画協会が東京都青少年健全育成条例改正に声明文、アニメフェア中止も
日本動画協会が東京都青少年健全育成条例改正に声明文、アニメフェア中止も
-
 漫画規制の都条例、「ネギま!」著者がTwitterでファンと討論
漫画規制の都条例、「ネギま!」著者がTwitterでファンと討論
-
 出版倫理協議会、「青少年健全育成条例改正案」可決に“強い憤り”を表明
出版倫理協議会、「青少年健全育成条例改正案」可決に“強い憤り”を表明
-
 本日16時半から……ちばてつや氏らによる「都青少年育成条例断固反対!」会見を生で
本日16時半から……ちばてつや氏らによる「都青少年育成条例断固反対!」会見を生で
-
 グリー、青少年の保護・健全育成に向けた取り組みを強化……ペナルティ引き上げ、年齢制限細分化など
グリー、青少年の保護・健全育成に向けた取り組みを強化……ペナルティ引き上げ、年齢制限細分化など
-
 TCA、「青少年の携帯利用電話利用について」ページを新設 ~ フィルタリングやSIMを解説
TCA、「青少年の携帯利用電話利用について」ページを新設 ~ フィルタリングやSIMを解説
-
 GREE、青少年の保護・健全育成に向けた取り組みを強化
GREE、青少年の保護・健全育成に向けた取り組みを強化
-
 東京都“非実在青少年条例改正案”FAQを公開~しずかちゃんの入浴、綾波レイのヌードはOK
東京都“非実在青少年条例改正案”FAQを公開~しずかちゃんの入浴、綾波レイのヌードはOK
-
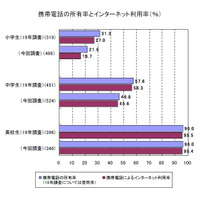 小中学生と高校生の保護者で、大きな意識の差――内閣府、青少年のネット環境調査
小中学生と高校生の保護者で、大きな意識の差――内閣府、青少年のネット環境調査