【テクニカルレポート】しゃべってコンシェルにおける質問応答技術……NTT技術ジャーナル
エンタープライズ
モバイルBIZ
-

10G光回線導入レポ
-
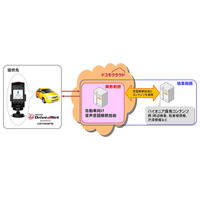
ドコモとパイオニア、「しゃべってコンシェル」の自動車向け応用技術を共同開発
-
ドコモ、「電話帳」と「spモードメール」をクラウド化……SNS連携も用意、「しゃべってコンシェル」も機能拡張
しゃべってコンシェル
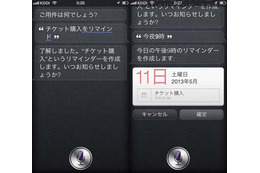
「しゃべってコンシェル*」は,NTTドコモが提供する音声エージェントサービスです.スマートフォンに音声で話しかけるだけで端末機能の呼び出しや各種アプリケーションの実行などを行うことができます(1).本サービスは,2012年3月のリリース以降,2012年10月までに400万ダウンロード,1億8000万回のアクセスを達成するなど,人気のサービスとなっています.
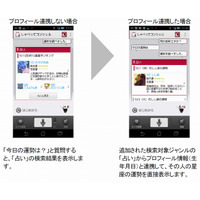
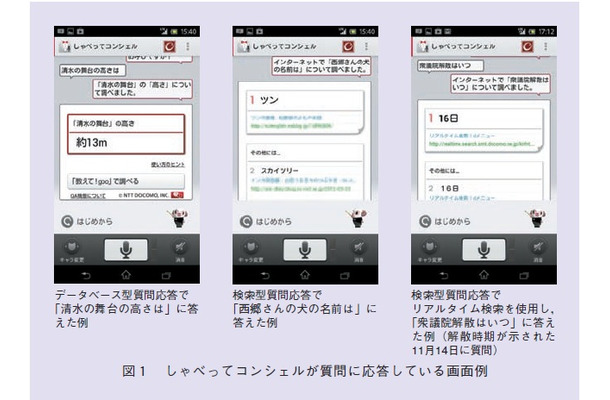
しゃべってコンシェルは,2012年6月にバージョンアップされ,その際にQ&A機能,すなわちユーザの質問に応答する機能が追加されました.この機能によって,例えば図1のように,ユーザのさまざまな質問に答えることができるようになりました.ここでは,このQ&A機能を支える質問応答技術について解説します.なお,Q&A機能は,NTTメディアインテリジェンス研究所の技術を基に,NTTドコモが開発したものです.
質問応答技術
質問応答技術とは,ユーザの質問にずばり回答を返す技術のことです(2).例えば,「世界で一番高い山は?」という質問に「エベレスト」と回答するような技術です.しゃべってコンシェルはこの技術を用いて質問に答えています.
ユーザの質問は多種多様なため,あらかじめすべての質問を予想し,その答えを準備しておくことは困難です.そこで質問応答技術では,人間が質問から回答を導く手順をアルゴリズムとして実装し,多様な質問に答えられるようにしています.
人間は質問に答えるとき,まず,自分の知識で答えられるものであれば,それを用いて答え,もし答えを知らなければ,図書館に行ったり,インターネットを検索したりして,その答えを探します.質問応答技術も同様です.
しゃべってコンシェルは,自分の知識として,知識データベースを保持しています.そして,ユーザ質問に対する答えが知識データベースにあれば,それを用いて回答し,見つからなければ,インターネットを検索し回答を探します.
知識データベースには,ユーザが頻繁に尋ねるような事柄についてのデータを格納しておきます.そうすることで,よく聞かれる定番質問には,即座に正確な回答を返すことができます.知識データベースでカバーできない事柄については,インターネット検索を用いることで,必ずしも正確な回答ではないかもしれませんが,ユーザの質問を無視することなく,何らかの回答を返します.何らかの回答を返すことは,ユーザ満足度の観点からとても重要です.
知識データベースを用いて回答する手法をデータベース型質問応答と呼び,インターネット検索を用いて回答する手法を検索型質問応答と呼びます.
データベース型質問応答
データベース型質問応答が扱うものとして,私たちは,ある対象についての属性を尋ねる質問に着目しました.このような質問は定番質問として多く見られるタイプで,例えば,「エベレストの高さは?」「日本の首相は?」「オバマ大統領の誕生日は?」などが挙げられます.「エベレストの高さは?」であれば,対象が「エベレスト」であり,属性は「標高」となります.
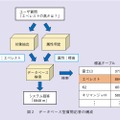
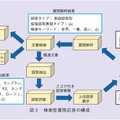
データベース型質問応答では,まずユーザの質問を解析し,質問から対象と属性を抽出します.そして,知識データベースから,対象の属性値を検索します.エベレストの例の場合,知識データベース中の「標高」テーブルから,「エベレスト」の値を探すことになります.データベース型質問応答の構成を図2に示します.
一連の処理においてもっとも困難なポイントは,質問からの対象と属性の抽出です.なぜなら,対象の属性を尋ねる質問は,必ずしも「対象の属性は?」という単純な表現だけでなされるわけではなく,非常に多様だからです.エベレストの例でいうと,「エベレストって何メートル?」「エベレストはどのくらい高い?」「高さ教えて,エベレストの」など,いろいろな言い回しが考えられ,これらの表現のどれからも正しく「エベレスト」と「標高」を抽出することは容易ではありません.
そこで私たちは,機械学習を用いることでこの問題を解決しました.機械学習とは,事例から統計処理によって,計算機に物事の判断基準を学習させる枠組みのことです.
具体的には,対象の個所をラベル付けした質問文を大量に準備し,質問文中の単語系列がどのような場合に対象となるかという基準を学習しました.また,属性があらかじめ分かっている質問文を大量に準備し,質問中の単語列の情報から,特定の属性についてであると判断する基準を学習しました.結果として,いろいろな言い回しであっても,質問から高精度な対象と属性の抽出を実現することができました.
※本記事は日本電信電話(NTT)が発行する「NTT技術ジャーナル誌 Vol.254,No.2 pp.56-59,2013」の転載記事である