爆発的に増加するM2Mデータを分散処理……データ量を100分の1に!富士通研究所が発表
エンタープライズ
企業







発表にあたって、ヒューマンセントリックコンピューティング研究所 所長 飯田一朗氏が、同研究所が掲げる「ヒューマンセントリックインテリジェントソサエティ」について説明。飯田氏は、1990年代のICTはコンピュータセントリックであり専門家のものだったという。続く2000年代はネットワークセントリックにシフトし、ICTが誰でも使えるようになったとした。そこで、同研究所では2010年からのICTをヒューマンセントリック(人間中心)に考えたものにする必要があるとしている。
とくに現在は、クラウドコンピューティング、センサ技術、モバイル通信といった技術を背景にしたビッグデータを前提としたシステムやソリューションが注目されているが、人とコンピュータの能力差や、人間がデータをコンピュータに入力しなければならない現状が、反面、「人がコンピュータに使われている現状もある(飯田氏)。」という弊害も生んでいるとした。
このような現状を改善するには、M2M技術によって、人々を取り巻く様々なデバイスやセンサーから直接実世界の情報・状態を読み取り、そのデータをクラウドに集約し分析・処理することで、状況に応じたサービスや価値あるしくみを提供することが重要であるという。飯田氏は、これを実現する技術基盤が「インテリジェントソサエティ」であると述べる。
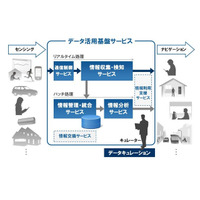
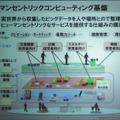
続けて飯田氏は、富士通ではビッグデータの活用基盤に利用できるクラウドサービスを1月に発表しているが、今回の発表は、そのビッグデータ活用基盤サービスを効率的に利用するため、イベント駆動型のデータ収集・処理基盤となるものだと紹介した。ここでの、イベント駆動型というのは、ユーザーが端末を操作したりデータを入力するのではなく、ユーザーの行動や状態をセンシング技術によって取り込むことを意味している。
ここで、発表者が同研究所 主任研究員 佐々木和雄氏に交代し、具体的な処理技術の紹介に移った。佐々木氏は、実際にセンサー等を使ってビッグデータをクラウドに集約させようとしても、現状ではいくつかの課題があり、そのうち一番大きな問題は、ビッグデータを集約するためのコストだと述べた。ペタバイトクラスのデータになると、ネットワークリソースとストレージなどのITリソースを大量に消費しなければならない。象徴的なのは、すでに通信事業者の間では、通信トラフィックの増大がサービス維持やQoSに多大な影響を与え、従量課金や帯域制限などの動きも実際に起こっていることだとした。
ちなみに、佐々木氏によれば、通信端末は現在の90億台から2020年に240億台まで増加し、そのうちM2M関係の機器は30億台から120億台にまで増えると予想されているそうだ。このような状況では、どれくらいのネットワーク帯域や通信コストになるのかというと、4万人規模の電力センシングを行った場合、ネットワーク帯域は常時300Mbpsが必要となり、蓄積されるデータは100TB/月に達する。1万台の機器を無線通信により稼働ログを収集するとしたら、通信コストは500~1,000万円/月だそうだ。
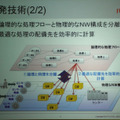
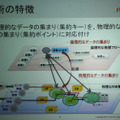
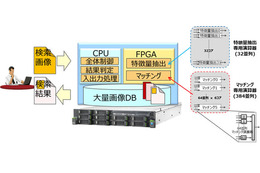
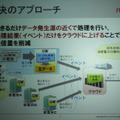
このようにヒューマンセントリックなクラウドソリューションを実用化するためには、これらを圧縮する方法が不可欠となる。一般的に、ビッグデータを意思決定やBIなどに活用する場合、最終的に必要なのは、事業拠点ごと、一定期間ごとに集計されたデータである。生データを詳細に分析したいのはむしろ現場であることが多い。この点に着目した、同研究所の解決アプローチは、できるだけデータの発生源近くに、データを処理し、集計したり計算した結果だけを上流に投げるようなゲートウェイ(GW)を設置する方法。
センサや機器とクラウドの間に設置されるGWは、集計データの前処理などを行うことが主な機能なので、その本質はソフトウェアで実現可能である。そのため、GWには、専用の機器を開発してもよいし、ルータにそのようなソフトウェアを実装することもできる。もちろん、PCなども利用可能であり、より個人との紐づけを強化するなら、スマートフォンにGWソフトウェアを実装してもよいそうだ。
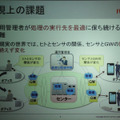
GWによって、センサーやデバイスからのデータをクラウドに集約する場合の効率化は実現できるが、それだけでは、実世界の人間の動きや情報を正しくセンシングするには問題が残る。GWにスマートフォンを利用すれば紐づけは強くなるが、そうでない機器を利用する場合、その人がどこで作業しているのかを把握しなければならない。これは、どのセンサーのどのタイミングの情報が、目的としている人のデータかどうか、ということを識別しなければならないことを意味する。
佐々木氏は、この課題を解決するため、物理的なGWの配備や構成と、論理的なデータの収集経路を抽出しながら、動的にかつ最適なGWの配備候補を抽出する分散処理フレームワークを開発したという。集計のための処理フローと、物理的なネットワーク構成を分離できるわけだ。
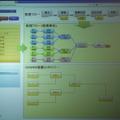
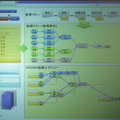
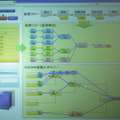
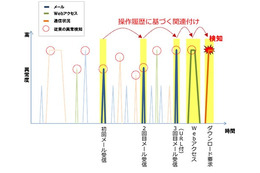
発表では、この技術のデモとして、消費電力を測定できるスマートタップによって、ユーザー、部署、全社といった単位で消費電力をモニタするシステムを用意した。管理画面では、どのタップにどの部署の誰のPCが接続されたか把握できるようになっており、プラグを移動させると、集計のための処理フローが自動的に切り替わっていた。
佐々木氏は、この技術を導入することで、通信トラフィックの削減、GWで前処理を行うことによるクラウド上の処理のレスポンス向上、GWによるある程度の自律運転が可能になること、ネットワーク構成とユーザー情報の抽出・識別による運用管理コストの低減などの効果が期待できるとした。そして、同研究所の試算では、デモのような電力センシングの例で、トラフィックが320Mbpsから3.2Mbpsに、104TB/月のデータサイズが1.04TB/月と、ともに1/100まで削減できるとのことだ。
今後は、配置候補抽出アルゴリズムを制御系などに応用することで、大量のGWの効率的な管理技術の確立を進めるという。なお、この技術の実用化は2013年を目標としている。