三菱電機、機密情報を高精度で自動検出するソフトウェアを開発
エンタープライズ
その他

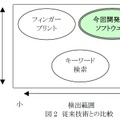
現在の情報漏洩防止ソフトウェアでは、機密文書ファイルの検出に「フィンガープリント」(ハッシュ値に変換した証明データと、検索対象から変換した証明データの両方を突き合わせて、照合する方法)や「キーワード検索」が用いられているが、フィンガープリントは検出対象があらかじめ登録した機密文書ファイル(完全一致)とその一部改変ファイル(部分一致)に限られ、キーワード検索は高い検出精度を得られるキーワードの選定に困難がともなうという問題があった。
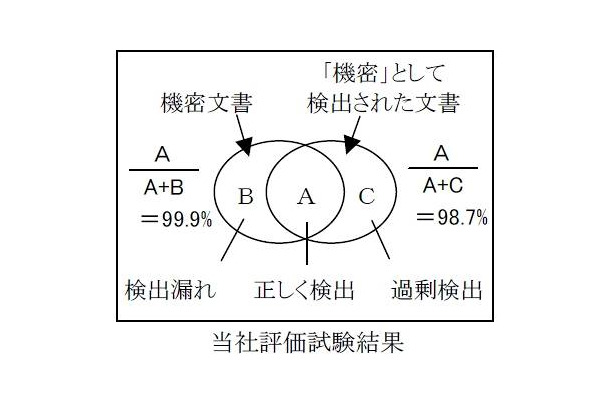
三菱電機が開発したソフトでは、キーワード検索に加えて、機密と非機密に分けて登録した文書ファイルから出現頻度の高い文字列(統計的特徴)を自動で学習する「学習型フィルター」により、従来検出できなかった内容の類似した文書ファイルも検出する。同社が実施した評価試験では、約14,000件の文書ファイルにおいて、機密文書ファイルの99.9%(従来89.7%)を「機密」として検出し、検出漏れが少ないことを確認した。また、「機密」として検出された文書ファイルの98.7%(従来96.4%)が機密文書ファイルであり、過剰検出も少ないことを確認、検出漏れと過剰検出がともに少ない高精度検出を実現した。
キーワード検索による機密文書ファイルの検出精度は設定するキーワードに左右されるため、複数の部署を網羅するには、各部署の機密に精通している者がキーワードを設定しなければならず、過剰検出も増えてしまうため、適切なキーワードを設定することが難しいという課題があった。同社の学習型フィルターは、機密に属する統計的特徴と非機密に属する統計的特徴を自動で学習するので、人手による複雑な条件設定作業が不要とのこと。今後は、メールに含まれる機密情報を検知するシステムや、PCやサーバ内の機密文書ファイルを検出するシステムなどの開発を行い、2009年度内の事業化を目指す。
関連リンク
関連ニュース
-
 日立ソフト、電子文書などのコンテンツ承認基盤ソフト「ContentsGate」を販売開始
日立ソフト、電子文書などのコンテンツ承認基盤ソフト「ContentsGate」を販売開始
-
 富士通研、宛先ミスから機密情報流出まで対策が可能な、メール情報漏洩対策技術を開発
富士通研、宛先ミスから機密情報流出まで対策が可能な、メール情報漏洩対策技術を開発
-
 ベリサイン、新手の「中間者攻撃(Man-In-The-Middle攻撃)」への注意を呼びかけ
ベリサイン、新手の「中間者攻撃(Man-In-The-Middle攻撃)」への注意を呼びかけ
-
 ALSI、企業間でセキュアなデータ交換を行う「SOM Creator」発売開始
ALSI、企業間でセキュアなデータ交換を行う「SOM Creator」発売開始
-
 日本ユニシス、「情報セキュリティ実装・運用評価サービス」を提供開始
日本ユニシス、「情報セキュリティ実装・運用評価サービス」を提供開始
-
 日本ワムネット、ファイル共有「GigaCC」に誤送信・漏洩防止できる「上長承認機能」を追加
日本ワムネット、ファイル共有「GigaCC」に誤送信・漏洩防止できる「上長承認機能」を追加
-
 SBテレコム、仮想化サーバプラットフォームで提供する「マネージドゲートウェイ ホスティング」開始
SBテレコム、仮想化サーバプラットフォームで提供する「マネージドゲートウェイ ホスティング」開始
-
 ネットで売買される“トロイの木馬”〜RSAセキュリティによる犯罪レポート
ネットで売買される“トロイの木馬”〜RSAセキュリティによる犯罪レポート
-
 ZoneAlarm ForceField、Internet Explorer 7の脆弱性を悪用したダウンロード攻撃を阻止
ZoneAlarm ForceField、Internet Explorer 7の脆弱性を悪用したダウンロード攻撃を阻止
-
 「110万ドル」「419条」「742/320ドメイン」って?〜数字で見るサイバー攻撃、マカフィー発表
「110万ドル」「419条」「742/320ドメイン」って?〜数字で見るサイバー攻撃、マカフィー発表
-
 【SaaS World 2008 Vol.2】「他企業とのコラボにも積極的に取り組む」——NTT
【SaaS World 2008 Vol.2】「他企業とのコラボにも積極的に取り組む」——NTT
-
 CSK-ITマネジメント、企業データ保管サービス「ほふみ」を開始〜重要文書を50万枚規模で保管
CSK-ITマネジメント、企業データ保管サービス「ほふみ」を開始〜重要文書を50万枚規模で保管
-
 【インタビュー】クラウド時代の電子文書セキュリティ——配布後も制御可能なSaaS型サービスの実力
【インタビュー】クラウド時代の電子文書セキュリティ——配布後も制御可能なSaaS型サービスの実力
-
 シマンテック、IRM戦略の一環として「Symantec Data Loss Prevention version 9.0」などを発表
シマンテック、IRM戦略の一環として「Symantec Data Loss Prevention version 9.0」などを発表
-
 クリアスウィフトと日立ソフト、情報漏えい防止のソリューションを共同開発
クリアスウィフトと日立ソフト、情報漏えい防止のソリューションを共同開発
-
 BIGLOBEとリアルコム、機密文書などをセキュアに社内外で共有するコラボソリューション提供開始
BIGLOBEとリアルコム、機密文書などをセキュアに社内外で共有するコラボソリューション提供開始
-
 KDDI研究所、独自の超高速秘密分散方式で秘密情報を保護する管理システムを開発
KDDI研究所、独自の超高速秘密分散方式で秘密情報を保護する管理システムを開発
-
 ブラピ&クルーニー出演、ヴェネチア映画祭オープニング予告編公開
ブラピ&クルーニー出演、ヴェネチア映画祭オープニング予告編公開
-
 センドメール、機密情報漏えい防止の新機能として「Document Fingerprinting」を発表
センドメール、機密情報漏えい防止の新機能として「Document Fingerprinting」を発表
-
 三菱電機IT、統合ログ収集・分析システム「LogCatcher for LanScope Cat」発売
三菱電機IT、統合ログ収集・分析システム「LogCatcher for LanScope Cat」発売
-
 日本HP、データ完全消去による情報漏えい対策など「Compaq」ノートPC5製品
日本HP、データ完全消去による情報漏えい対策など「Compaq」ノートPC5製品