単一部品にとどまらず、部品同士の幾何的関係性まで説明可能な点群言語モデルを開発
ポイント
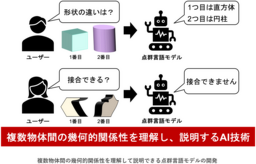
・ 従来の視覚言語モデルは単一物体の理解に留まっていたが、複数物体を見比べて「どの部品が接合するか」などまで理解し、説明できる点群言語モデルを開発
・ 複数物体の幾何的関係性を学習する独自データセットとモデル設計により、部品同士の接合関係や形状変化について説明できることを実証
・ 部品の接合判断は設計・製造の根幹工程であり、本技術は製造現場における専門家の判断の自動化・効率化に貢献することが期待される
【画像:https://kyodonewsprwire.jp/img/202605219453-O1-2TX9y74s】
概 要
国立研究開発法人産業技術総合研究所(以下「産総研」という)人工知能研究センター 山田 亮佑 研究員、Qiu Yue 主任研究員、井手 康允 リサーチアシスタントは、複数物体の幾何的関係性を理解し、説明可能な点群言語モデルを開発しました。
複数物体や部品を見比べて、その形状の違いや接合関係を判断することは、製造現場において重要な工程です。近年製造現場でもAI技術の導入が進められていますが、従来のAIモデルは単一物体を認識・説明することにとどまり、複数物体間の幾何的関係性を理解することは困難でした。今回、複数物体を比較し、その幾何的関係性を理解するための新しい学習・評価基盤として、約7万件の高品質な三次元点群データとそれらに対する質問応答が付与されたデータセット「MO3D」を構築しました。さらに、このデータセットを用いて、複数物体を部品レベルで見比べ、「どの部品同士が接合するか」や「形状のどこが異なるか」といった内容を文章で説明できる点群言語モデル「Multi-3DLLM」の開発に成功しました。評価実験では、既存の視覚言語モデルを上回る性能を達成しました。特に、MO3Dを使用した物体比較、物体接合、物体変化のすべての説明課題において、Multi-3DLLMの質問正答率が、従来手法と比較して約1.8倍に向上する性能改善を示しました。本技術により、複数物体の幾何的関係性を理解し、それを言葉で説明できるAI(人工知能)モデルが実現されます。これによって、ロボットによる部品選別や組立支援、形状比較、3D設計ソフトにおける編集支援など、設計・製造分野を中心とした幅広い領域での作業効率向上への貢献が期待されます。さらに、本研究で整備したデータセット「MO3D」は、複数物体の幾何的関係性理解に関するフィジカルAI研究のさらなる発展にも役立つと考えられます。
なお、本研究成果は、IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026(2026年6月3日~7日、米国 デンバー)で発表予定です。また、今回開発した点群言語モデル「Multi-3DLLM」およびデータセット「MO3D」はGitHubにて公開予定です。
下線部は【用語解説】参照
研究の社会的背景
2026年現在、AI技術は、文章・画像を理解して説明する段階から、実世界にある空間・物体を正確に把握し、活用する段階へと進みつつあります。例えば製造現場では、複数の工業部品が正しく組み合わさるかを確認したり、部品形状の違いを比較したりすることが重要工程となっています。しかし、従来の視覚言語モデルは、主に画像または三次元点群によって単一の物体を理解し、説明することにとどまり、複数物体を同時に扱って、「どの部品同士が接合するのか」「どの部品が異なるのか」といった幾何的関係性を詳しく説明することは困難でした。
このような背景から、“複数物体を見比べ、形状の違いや組み合わせ、変化を理解し、言語で説明できるAI”が求められています。本研究は、このような社会的ニーズに応え、設計・製造をはじめとする応用分野において、人の判断を支援・効率化する新しいAI技術の実現を目指した研究開発です。
研究の経緯
AIモデルの性能向上には、大規模データセットに基づく学習が重要です。産総研は、視覚と言語の統合モデルやシミュレーションを活用し、実世界の認識・理解の高度化に取り組んでいます。実世界で柔軟に適応するロボット知能の基盤構築を目指し、三次元物体や環境を的確に認識するための汎用かつ高性能なAI技術を開発してきました。
こうした知見を生かして、本研究では、複数物体を同時に扱い、それらの幾何的関係性を理解して言葉で説明できる、新しい点群言語モデルの開発に取り組みました。なお、本研究開発は、産総研政策予算プロジェクト「フィジカル領域の生成AI基盤モデルに関する研究開発」に基づき実施されました。
研究の内容
本研究では、複数物体を見比べて、その形状の違いや幾何的関係性を理解できるAI技術の実現を目指しました。
まず、複数物体の幾何的関係性を学習・評価するために、大規模な質問応答データセット「MO3D」を構築しました。MO3Dは、三次元点群データセットであり、複数物体の幾何的関係性理解を対象とした学習・評価を可能にした点が特徴です。主に2〜3個の三次元物体を組み合わせた入力に対して、「どの部品同士が接合するか」や「どの形状が異なるか」といった比較もしくは関係性の理解を問う約7万件の質問応答データから構成されています(図1)。このような複数物体の幾何的関係性に特化した大規模データセットはこれまで存在していませんでしたが、学習・評価可能なデータセットとしてわれわれが独自に構築しました。
【画像:https://kyodonewsprwire.jp/img/202605219453-O2-ur1kRR6A】
次に、MO3Dを用いて、複数の三次元点群を同時に入力し、物体間の関係性をパーツレベルで理解して文章で説明できる点群言語モデル「Multi-3DLLM」を開発しました。本モデルでは、複数物体から獲得される特徴を統合し、相互の幾何的な関係性を直接捉える構造を導入することで、細かな幾何的対応関係の理解を可能にしています。三次元点群を用いることで、画像のみでは捉えにくい幾何形状の違いまでを説明することができます。
評価実験では、MO3Dデータセット全タスク(物体比較、物体接合、物体変化)において、Multi-3DLLMの平均質問正答率が、既存の視覚言語モデル(LLaVA[1], Molmo[2], PointLLM[3], ShapeLLM[4], MiniGPT-3D[5])と比較して高精度な性能を示しました。特に、MO3Dにおいて物体比較を文章で説明する課題では、既存の視覚言語モデル(LLaVA)の質問正答率が11.7 %であるのに対して、われわれが開発したMulti-3DLLMは33.8 %の質問正答率を達成しました(図2)。これは、複数物体間の幾何的関係性を学習できるデータ設計とモデル構造の有効性を示す結果です。
【画像:https://kyodonewsprwire.jp/img/202605219453-O3-3nBmiv6R】
このように、本研究により、従来は難しかった複数物体の幾何的関係性の理解と説明を、AI技術によって実現しました。設計や製造における部品の接合判断や形状比較など、これまで人の専門的な判断を必要としていた作業の効率化・高度化への応用が期待されます。例えば、CADやCAEなどの3D設計ソフトを用いた製品開発で、「椅子の背もたれを現状より○○センチメートル高くする」といった指示を言葉で与えられるようになれば、設計作業が効率化されます。また、本研究で構築したデータセット「MO3D」の公開により、複数物体の幾何的関係性理解に関するAI研究のさらなる発展が期待されます。
今後の予定
今後は、より多様で複雑な複数物体の組み合わせに対応するため、複数物体の関係性を扱う三次元点群データセットのさらなる拡張を進めます。特に、製造現場などで扱われる複雑な工業部品や、多段階の組立関係を含むデータを追加することで、より実環境に近い状況に対応可能なAIモデルの構築を目指します。また、現在は主に2〜3個の物体間の比較および関係性理解を対象としていますが、今後はより多数物体を同時に扱い、より複雑な関係性や幾何構造を理解できるAIモデルへの発展を検討しています。
学会情報
学会名:The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026
発表タイトル:Beyond Single Object: Learning 3D Relations with Large Language Models
著者: Kohsuke Ide, Ryousuke Yamada, Yue Qiu, Xianzheng Ma, Yoshihiro Fukuhara, Hirokatsu Kataoka, Yutaka Satoh
入手先
学習済みモデル(Multi-3DLLM)と学習・評価データセット(MO3D)は下記のサイトからダウンロード可能です。
(https://github.com/KohsukeIde/BeyondSIngleObject)
参考情報
[1] Liu, H.; Li, C.; Wu, Q.; Lee, Y. J. “Visual Instruction Tuning,” Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2023, vol. 36, p. 34892-34916. DOI: 10.52202/075280-1516.
[2] Deitke, M.; Clark, C.; Lee, S.; Tripathi, R.; Yang, Y.; Park, J. S.; Salehi, M.; Muennighoff, N.; Lo, K.; Soldaini, L.; Lu, J.; Anderson, T.; Bransom, E.; Ehsani, K.; Ngo, H.; Chen, Y.; Patel, A.; Yatskar, M.; Callison-Burch, C.; Head, A.; Hendrix, R.; Bastani, F.; VanderBilt, E.; Lambert, N.; Chou, Y.; Chheda, A.; Sparks, J.; Skjonsberg, S.; Schmitz, M.; Sarnat, A.; Bischoff, B.; Walsh, P.; Newell, C.; Wolters, P.; Gupta, T.; Zeng, K.; Borchardt, J.; Groeneveld, D.; Nam, C.; Lebrecht, S.; Wittlif, C.; Schoenick, C.; Michel, O.; Krishna, R.; Weihs, L.; Smith, N. A.; Hajishirzi, H.; Girshick, R.; Farhadi, A.; Kembhavi, A. “Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2025, p. 91-104. DOI: 10.1109/CVPR52734.2025.00018.
[3] Xu, R.; Wang, X.; Wang, T.; Chen, Y.; Pang, J.; Lin, D. “PointLLM: Empowering Large Language Models to Understand Point Clouds,” Proceedings of the European Conference on Computer Vision (ECCV), 2024, vol. 15083, p. 131-147. DOI: 10.1007/978-3-031-72698-9_8.
[4] Qi, Z.; Dong, R.; Zhang, S.; Geng, H.; Han, C.; Ge, Z.; Yi, L.; Ma, K. “ShapeLLM: Universal 3D Object Understanding for Embodied Interaction,” Proceedings of the European Conference on Computer Vision (ECCV), 2024, vol. 15101, p. 214-238. DOI: 10.1007/978-3-031-72775-7_13.
[5] Tang, Y.; Han, X.; Li, X.; Yu, Q.; Hao, Y.; Hu, L.; Chen, M. “MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors,” Proceedings of the 32nd ACM International Conference on Multimedia. 2024, p. 6617-6626. DOI: 10.1145/3664647.3681257.
用語解説
点群言語モデル
三次元点群を理解し、その内容を文章として説明したり、言葉による指示に応答したりできるAIモデル。物体の形状や構造を認識し、人と自然言語で対話できることが特徴。
三次元点群
三次元空間内の物体や環境の形状を、多数の三次元座標の集合として表現したデータ形式。各点は位置情報を持ち、物体の形や奥行きを表現できるため、ロボットや3D認識AIなどで活用されている。
データセット
AIモデルの学習や性能評価に用いられるデータの集合。画像、文章、三次元データなどを大量に含み、AIはこれらのデータから特徴や規則性を学習することで、認識や推論を行えるようになる。
視覚言語モデル
画像や映像などの視覚情報と言葉を統合して理解するAIモデル。画像の内容を文章で説明したり、画像に関する質問に答えたりすることができる。
質問応答データ
AIモデルに与える、質問とその正解となる回答を対となったデータ。AIは大量の質問応答データを学習することで、入力内容を理解し、適切な回答を生成できるようになる。
プレスリリースURL
https://www.aist.go.jp/aist_j/press_release/pr2026/pr20260525/pr20260525.html