コスト構造を見直し、迅速なサービス提供へ——リクルートのシステム構築のポイント
エンタープライズ
その他
-

10G光回線導入レポ
-

【ビデオニュース】効果的なストレージ活用と投資——ネットアップ
-

【ビデオニュース】簡単・迅速にテスト環境を用意し、ワークロードを再現!——ネットアップ「SnapManager for Oracle」






リクルート MIT United システム基盤推進室エグゼクティブマネージャーの米谷修氏は同社のシステム構築の課題について話し始めた。氏は4月下旬に開催された「Oracle OpenWorld Tokyo 2009」のネットアップのセッションの講演に登壇した。詳細な構成は明らかにされなかったが、概要とポイントを講演のなかから紹介しよう。
リクルートでは、ここ最近のPV増加に対して、各サービスが必要に応じてシステムの最適化を行っていた。同社内のサービスは次々に新しいものが立ち上がり、新規ビジネスへの迅速な対応が求められていたが、サービス提供がビジネススピードに応えきれないなど、インフラに課題が残っていた。さらに、これまで順次インフラを拡大してきたため、4つのデータセンターにまたがってサービスを展開。調査してみたところ、ストレージでの利用率は45%であることも判明した。このような無駄はコストにも反映される。サービスを広げるたびにインフラの増改築・構築を行っていたため、エンジニアリングの人件費をいかに抑えるかということも過大となっていた。同社のインフラコストの約4割が増改築等のインフラ関連の人件費であったという。
「ネットの世界は非常に変化が激しい。これまではハードウェアの発注から設計・導入という形でどうしても時間がかかていた。このインフラの機動力をいかに上げるのか?というところも課題だった」(米谷氏)。
これらの課題をうけて、同社が考えたインフラのコンセプトは次のようなものになった。
1)ハードウェアの構成/配置は統一し、余剰リソースの利用効率を高める
2)ネットワーク/ストレージは統合・仮想化し、論理的に個別利用
3)エンジニア作業/構成管理を自動化し、機動性と省力化を実現
4)コストパフォーマンスの高いサーバをスケールアウトにて拡張
5)インフラ構成をシンプルにし、順次拡大するスモールスタート構成
これまではサイト規模に応じてデータベースサーバなどは様々な機種を使っていたが、今回は1UのIAサーバに標準化。プール化のアーキテクチャーを導入し、必要に応じて提供・返却する仕組みを取り入れた。また、サーバをプール化してもネットワーク部がそれに対応していなければトータルのエンジニアリングコストは落とせないため、これまでセンターごとに分割配置していたロードバランサーやストレージなども全て統合した。さらに統合したネットワーク機器、ストレージ部分を論理的に分割し、各サイトごとに払い出す考え方を取り入れた。
全てではないが、リソースの割り当てや構成の変更はある程度テンプレート化し、ネットワーク機器の変更など自動化する取り組みに取り組んでいるという。「これはまだ完全な状態ではないが、これからチューニングしていくことで人件費を下げることができると考えている」。また、「デイリーサーバとCPUパワーが必要なところに関してはOracle RACを使ってグリッド型で対応するのがひとつ。小さなサービス(1台だとCPUパワーがあまってしまうようなところ)では仮想化の技術を使って1台のサーバを論理的に分割するアーキテクチャーを取り入れている」とも話した。
これらのアーキテクチャを実装するにあたってかなり数多くの検証を行ったというが、氏が挙げた下の写真のように4つに大別される。
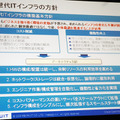
このうち次世代のITインフラストレージに求めるポイントは下記のようにまとめられた。
1)数万IOPSのトラフィックに対応できるスループットとトランザクション性能
2)オンラインでのバックアップパフォーマンス維持
3)Oracle環境での利用可能な仮想ストレージ技術
4)スモールスタートが可能で、ビジネスの成長に合わせて柔軟かつ迅速に拡張できる構成
5)可能な限り「無停止で拡張でき、大幅な設定変更や構成変更を伴わない
6)直感的な操作が可能で容易に運用ができること
7)製品の安定性とサポート体制
8)Oracle環境での利用実績
「ここから絞りこんでいった。まずは机上でかなり多くの製品を確認し、ある程度絞り込んで機能検証を行ったうえで、さらに絞り込んでつっこんだ検証を行った」。
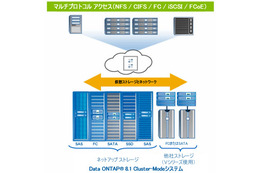
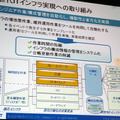
Oracle on NFS構成/NetApp FAS(SAN構成も同時に検証)と従来型のSAN構成/A社 SANという代表的なストレージベンダー製品を下の図のような環境で検証した。「検証を行うにあたっては、かなりの台数のサーバを用意して、実利用に近い負荷をかけて検証している。またIOのパターンに関してもオンライン系やバッチ系など様々なパターンで検証した」という。氏は検証のなかで役立ったツールとしてNetAppのSIOを挙げた。
「NetAppのFlexVolをもちろん使ったが、拡張・縮小は本当にできるのか、それで実際にそれが使えるのかというところも検証し、問題がないのを確認した。運用性に関しては、これまでSANで行っていた運用に比べると、かなり楽にできるということが現場の技術者からも聞くことがきくことができた」と、氏は評価する。
信頼性に関しては、RAID-DPとSyncMirrorを組み合わせてレベルの高い保護を実現している。「米国のユーザ企業に聞くと、ここまでやらなくてもいいんじゃないの?と言われるが、我々はデータベースをかなり大事なものととらえているので、ここまで信頼性を上げる構成を組んでいる。それでも心配だったので、米国企業のストレージ運用技術者に直接話をきいて本当に大丈夫なのかと確認した」ほどだという。
リクルートでは大小100のサイトを抱えているという。それらのサービスが、どれくらいブレイクするかというのはなかなか判断が難しい。そのためどうしても大きめにストレージを用意してしっていた。あるいは余分目にストレージをアサインしてしまうことが多かった。
結果として、同社はインフラコスト構造を見直しながら迅速な対応を行うことを目標に、ストレージを統合・仮想化。シンプルなインフラ構成にしつつ、ダイナミックな割り当てを実現してリソースを有効活用していくという方針をたてた。氏は「分割を排除し、ストレージの最適化をできたし、コストは運用部分を削減できた。FlexVolによるフレキシブルな対応も可能になった」と話す。オラクルの検証が終了したばかりだが、運用にも耐えられるだろうと話した。
関連リンク
関連ニュース
-
 【ビデオニュース】効果的なストレージ活用と投資——ネットアップ
【ビデオニュース】効果的なストレージ活用と投資——ネットアップ
-
 【ビデオニュース】簡単・迅速にテスト環境を用意し、ワークロードを再現!——ネットアップ「SnapManager for Oracle」
【ビデオニュース】簡単・迅速にテスト環境を用意し、ワークロードを再現!——ネットアップ「SnapManager for Oracle」
-
 シスコとネットアップ、Oracle環境における10Gb Ethernetの性能を検証
シスコとネットアップ、Oracle環境における10Gb Ethernetの性能を検証
-
 ネットワールド、米BLADE社のイーサスイッチ「RackSwitch」シリーズを販売開始
ネットワールド、米BLADE社のイーサスイッチ「RackSwitch」シリーズを販売開始
-
 ネットアップ、転送速度を1.8倍に向上させたクラスタストレージ「FAS3160」
ネットアップ、転送速度を1.8倍に向上させたクラスタストレージ「FAS3160」
-
 ネットアップ、仮想テープライブラリ製品に重複排除機能を搭載
ネットアップ、仮想テープライブラリ製品に重複排除機能を搭載
-
 ネットアップ、業界で初めて新規格FCoE対応ストレージを発表〜シスコNexus 5020に対応
ネットアップ、業界で初めて新規格FCoE対応ストレージを発表〜シスコNexus 5020に対応
-
 シスコ他、12社による「Data Center 3.0」仮想化環境の相互接続検証トライアル
シスコ他、12社による「Data Center 3.0」仮想化環境の相互接続検証トライアル
-
 ネットアップ、「NetApp Solution Best Practice 2008」を開催!
ネットアップ、「NetApp Solution Best Practice 2008」を開催!
-
 仮想化技術をさらに加速する6コアのサーバ向けCPU「Xeon」の7400番台が発表
仮想化技術をさらに加速する6コアのサーバ向けCPU「Xeon」の7400番台が発表
-
 ネットアップ、異なるベンダーのストレージを一括管理する仮想化システム
ネットアップ、異なるベンダーのストレージを一括管理する仮想化システム
-
 【「エンジニア生活」・技術人 Vol.21】ストレージに対するファンを作る——ネットアップ・三好慶太氏
【「エンジニア生活」・技術人 Vol.21】ストレージに対するファンを作る——ネットアップ・三好慶太氏
-
 ネットアップ、新ミドルレンジストレージシステムとアクセラレータを提供開始
ネットアップ、新ミドルレンジストレージシステムとアクセラレータを提供開始