
Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、音声合成(TTS)の精度向上や、文語表現を含む高度な言語理解を目的とした音声・テキストモデルの学習に最適化された、「日本語・1話者・古典朗読音声データセット」の提供を開始します。
本データセットは、日本の古典文学作品を題材とした朗読音声と、その内容を正確に書き起こしたトランスクリプトで構成されています。一人の日本人話者による安定した発話で、古典特有の文法構造や独特な言い回し、リズムを保ったまま読み上げるシーンを網羅しており、特定の声質を再現するモデルの構築や、現代語とは異なる韻律制御を伴う音声生成(AIボイス)の研究開発に適しています。長尺の朗読に含まれる息継ぎや抑揚の変化、文語体における読みの推定など、音響的特徴とテキストの相関を深く学習させることで、文脈を汲み取った自然な発話生成を可能にします。
本データは、Qlean Datasetが展開するAI開発用オリジナルデータラインナップ「AIデータレシピ」の一つとして提供され、オーディオブックの自動生成から、歴史的文献のデジタルアーカイブ化を支援する音声認識(ASR)の実装まで、実用的なAI開発を目指すフェーズでの活用を想定しています。
Visual Bankおよびアマナイメージズは、今後も日本の文化的資産を捉えた音声・言語データの提供を通じて、多様な表現を理解・生成するAIの研究・開発を支援していきます。
今回提供を開始する「日本語・1話者・古典朗読音声データセット」の概要

「日本語・1話者・古典朗読音声データセット」のユースケースイメージ
【研究用途】
- 文語体における音響的特徴の抽出と韻律解析現代語とは異なる文法構造や古い語彙に対し、一貫した話者がどのようにピッチや間(ポーズ)を配置するかを分析し、古典文学特有の韻律モデルを構築する研究に利用できます。
【産業用途】
- エンターテインメント向け高精度音声合成モデルの開発一人の話者による安定した長尺データを学習させることで、オーディオブックやデジタルコンテンツの読み上げに適した、情感豊かで一貫性の高い特定話者音声合成(TTS)エンジンの生成に利用できます。
- 文語表現を含む自動音声認識(ASR)の精度向上
日常会話とは語彙体系が異なる古典作品の音声データを用いることで、歴史的資料の翻刻支援ツールや検索システムにおける音声認識モデルの言語適応および認識精度の検証に利用できます。
【その他実需要】
- 古典文学の「音読自習」支援アプリの開発お手本となる正確な朗読音声とトランスクリプトを照合させることで、生徒の音読が正しく行われているかを判定・評価する、GIGAスクール構想下の教育用AIドリルや学習管理システムの実装に利用できます。
- 視覚障害者・学習困難者向けのアクセシビリティ向上
古典特有の難解な漢字や送り仮名、特殊な読み(歴史的仮名遣い)を、一貫した高品質な音声で提供することで、デジタル教科書の音声読み上げ機能や、バリアフリーな古典学習環境の構築に利用できます。
『Qlean Dataset(キュリンデータセット)』について
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する商用利用可能なAI学習用データソリューションです。
画像・動画・音声・3D・テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。また、国内・海外のデータホルダーやラジオ・新聞社・通信社等のメディアとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援します。
▶ Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
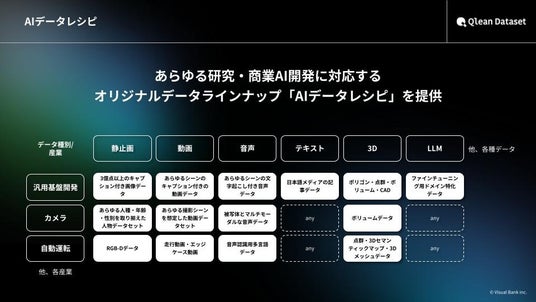


『Qlean Dataset』の提供するデータセット『AIデータレシピ』の特徴
- すべての被写体から同意取得
- 既存データは最短1日で納品可能
- カスタム撮影・収録・収集による独自データ構築にも対応
お問い合せ
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL:https://amanaimages.com/about/
Qlean Dataset Launches Single-Speaker Japanese Classical Audio Corpus
High-Quality Data for Advancing TTS and Classical NLP

Visual Bank Inc. (Minato-ku, Tokyo; Saneyuki Nagai, Representative Director and CEO) has announced the release of the "Japanese Single-Speaker Classical Literature Audio Dataset" through its AI training data solution, "Qlean Dataset," managed by its subsidiary, amanaimages inc. This dataset is specifically optimized for training speech and text models aimed at improving Text-to-Speech (TTS) precision and sophisticated linguistic understanding of classical Japanese expressions.
The dataset consists of high-quality audio recordings of Japanese classical literary works paired with accurate text transcripts. Featuring consistent speech from a single Japanese narrator, the corpus covers a wide range of complex grammatical structures, archaic phrasing, and rhythmic patterns unique to classical literature. This makes it an ideal resource for developing models that replicate specific voice characteristics or for research into prosody control in speech generation (AI Voice) involving non-contemporary Japanese. By enabling deep learning of the correlation between acoustic features and text-such as breath intake, intonation shifts in long-form narration, and phonetic estimation for classical script-the dataset facilitates the generation of natural, context-aware speech.
This release is part of the "AI Data Recipe" lineup, Qlean Dataset’s original series of high-quality data products for AI development. It is designed for practical AI implementation phases, ranging from the automated generation of audiobooks to the deployment of Automatic Speech Recognition (ASR) systems that support the digital archiving of historical documents. Visual Bank and amanaimages remain committed to supporting the research and development of AI capable of understanding and generating diverse expressions by providing premium audio and linguistic data that capture Japan’s cultural heritage.
Dataset Overview: Japanese Single-Speaker Classical Literature Audio Dataset

Potential Use Cases
【Research & Academia】
- Acoustic Feature Extraction and Prosodic Analysis of Classical Language:Used to analyze how a consistent speaker manages pitch and pauses relative to archaic grammatical structures and vocabulary, supporting the construction of prosody models specific to classical literature.
【Industrial Application】
- Development of High-Precision TTS Models for Entertainment:Training on stable, long-form data from a single speaker enables the creation of highly consistent and emotive TTS engines suitable for audiobooks and digital content.
- Improving Accuracy in ASR for Classical Expressions:
Provides linguistic adaptation for speech recognition models, allowing for higher accuracy in tools and search systems dedicated to transcribing or indexing historical documents.
【Educational & Social Implementation】
- Development of Self-Study Apps for Classical Literature:Allows for the implementation of AI-driven educational tools that compare a student's reading against professional reference audio and transcripts to provide real-time evaluation and feedback.
- Accessibility Improvements for the Visually Impaired or Learners with Difficulties:
Facilitates the creation of accessible educational environments and digital textbooks by providing high-quality, consistent audio for complex kanji and historical kana usage.
About Qlean Dataset
Qlean Dataset is a commercially cleared AI training data solution provided by Amana Images, a subsidiary of Visual Bank Group. The platform offers diverse data formats including image, video, audio, 3D, and text, as well as a specialized AI Data Recipe lineup developed through collaborations with major media organizations and data rights holders.
URL:https://qleandataset.visual-bank.co.jp/en
Contact
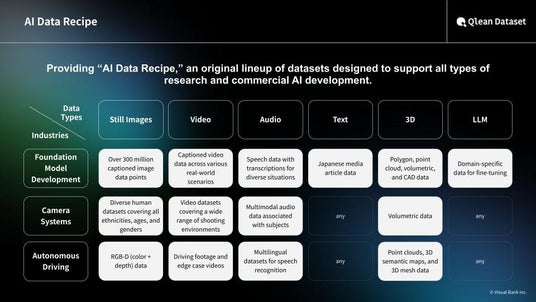


About Visual Bank Inc.
Visual Bank Group is a technology company developing data infrastructure and AI solutions that support advanced AI development. The company operates THE PEN, an AI tool for manga creators, and its subsidiary, amanaimages Inc., provides commercial digital content and AI training data solutions, including Qlean Dataset. Visual Bank is also a selected participant in GENIAC, a Japanese government initiative supporting the advancement of next generation AI technologies.
CEO: Saneyuki Nagai
Website:https://visual-bank.co.jp/en
企業プレスリリース詳細へ
PRTIMESトップへ