従来の課題
従来のAIや検索システムは、データ展開して処理する必要があり、膨大な計算資源を擁していました。
新AI構造「圧縮検索推論システム」・情報を意味単位で圧縮し、その圧縮データのままで検索。推論・応答生成が可能。
・数百ギガバイト規模の知識を数ギガバイト以下に圧縮。
・一般的なPCでも知的推論を実現。
・GPUを用いず、CPUのみで動作する軽量なAI基盤。

主な特徴

影響と安全性
他に類を見ない一般公開システム
「圧縮と推論を同時に実行する知能構造」は前例がありません。
現在までに同様の完成システムは確認できず、圧縮状態での検索・推論を実現した事例としては他に類を見ない一般公開システムと考えています。 既存の学術研究は概念段階や部分実装に留まっています。
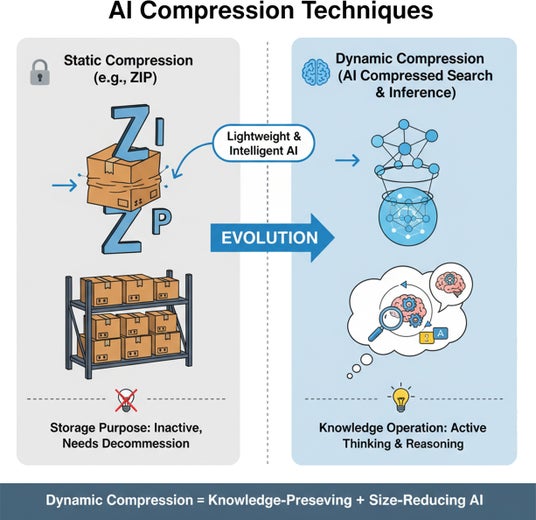
既存圧縮(ZIP)との違い
ZIP圧縮(従来)
・データを「バイト単位」で圧縮
・復元時には必ず解凍が必要
・目的:保存のための圧縮
本システム(新構造)
・情報を「意味単位」で圧縮
・解凍せずに理解・検索・推論が可能
・目的:思考のための圧縮
💡 AIの思考を高速化する「意味的な圧縮」とは?
「圧縮検索推論システム」の核となる「圧縮方法」は、分かりやすく言えば、「情報の中身を要約しながら、意味のつながりだけを残す仕組み」です。これは、私たちが長い本を読むときに、すべての文を記憶するのではなく、「重要な考え」や「関係性」だけを頭の中に残して理解するプロセスに非常に似ています。この知的技術は、データを大幅に削減しながらも、AIが知識の本質を理解し続けることを可能にします。
🧠 知的な圧縮の3ステップ
1. 要約する(「何が重要か」を抽出)
文章やデータ全体をそのまま記録するのではなく、意味ごとのまとまり(チャンク)に分け、「何にい
て語っているか」という重要な要素だけを抽出します。
例: 「犬が公園で楽しそうに走っている」
抽出: 「犬」「行動:走る」「状況:公園」「感情:楽しむ」といった形に要素化されます。
2. 関係をマップ化する(意味の流れを保存)
抽出した情報同士の関係性を、ネットワーク(グラフ)として保存します。この段階で、元の文章そも
のは消えてしまいますが、意味の流れは保持されます。
例: 「犬 → 走る → 公園 → 楽しむ」といった意味のつながりが明確に保存されます。
3. 圧縮状態で思考する(「つながり」で推論)
質問や命令を受け取ったとき、システムはこの意味ネットワークを辿って、最も近い知識や関連する概念
を“推測”します。つまり、データを元の形に解凍しなくても、「意味のつながり」だけで考えることがで
きるのです。
ZIP圧縮との決定的な違い
一般的な圧縮技術であるZIPファイルなどと、このシステムが行う圧縮には大きな違いがあります。

ZIPが「ファイルを畳む」だけの機能なら、このシステムは「知識をまとめて覚える」機能と言えす。この意味的な圧縮により、データ容量を100分の1以下に大幅に減らしても、AIは「知識の本質」を理解したまま推論を続けることができます。これは、人間の記憶や思考の仕組みに非常に近い、知的圧縮技術です。
圧縮検索推論システムは 情報を“削除”せず、“重みづけして整理”する方式を取っているため、重要な意味や関連性が失われることはほとんどありません。簡単に言えば、「忘れる」のではなく「優先順位をつけて覚える」仕組みです。
1. 情報は“意味単位”で圧縮される
圧縮時に削除されるのは、言葉の重複や文体的装飾など、“意味の伝達に不要な要素”だけです。「何が」「どう関係しているか」という意味構造は必ず残されます。これは人がノートを取るときに「重要語だけメモする」のと似ています。
2. 情報は“再構成可能”
推論時には、圧縮データをもとに意味を再展開して回答を生成します。つまり、圧縮は「失う」ではなく「折りたたむ」行為であり、必要に応じて展開して再現することができます。
3. AIデータでも安全
AI系の技術データやアルゴリズム構造など、論理の正確性が求められる情報も扱えます。なぜなら、システムは単なる文章ではなく、概念・変数・論理構造の関連グラフとして保存しているためです。そのため、「どの要素がどの関係にあるか」は厳密に保持されます。
4. 確率的欠落の防止
もし圧縮過程で情報が曖昧になりそうな場合、圧縮エンジンは「確信度(confidence weight)」を自動付与します。確信度が低い情報は消えずに保持され、再学習や再圧縮時に補強されます。
結論:
圧縮検索推論システムは、「情報を削る」圧縮ではなく、「情報を階層化し、意味で保持する」圧縮です。AI研究データ・モデル設計図・数式構造のような精度が必要なデータでも安全に圧縮・推論可能です。
開発者の視点
AIを“軽く、理解力の高い存在”として普及させることを目指しました。
圧縮とは単なる縮小ではなく、“意味を保ちながら思考する技術”です。
試験・調査による客観的結果
・自社調べ(ChatGPTによる)
・2025年10月時点
・圧縮済みWikipedia(約300万件)をGPU未搭載(CPU内蔵)PC環境で実行。
主に以下の3要素から構成される
1. 圧縮済みWikipedia(約300万件)
2. 意味検索推論エンジン(CPU対応)
3. Webインターフェース(Flask GUI)
これにより、ユーザーが自然文で質問を入力すると、AIは圧縮データベースを検索・推論し、即時に回答を生成する。
特性
特性 内容
検索速度 平均0.8秒/件(CPU: Intel i5相当)
ストレージ使用量 50GB以下(300万件圧縮済み)
GPU依存 なし
オフライン対応 完全対応
自動拡張 Wikipedia・社内DB対応
API連携 OpenAI・Claude・Geminiなど接続可
CompreSeed AI(第二形態)は、生成AIとのAPI接続により、「自社知識 × 外部知識」ハイブリッドAIチャットボットを構築できる。これは、従来のベクトルDBでは不可能だった統合型知識推論を実現している。
成果と評価
実験では、同一質問に対しCompreSeed AIとFAISSの回答精度を比較した結果、再現率(Recall)ではFAISSにやや劣るものの、精度(Precision)とコスト効率では圧倒的に優位であった。
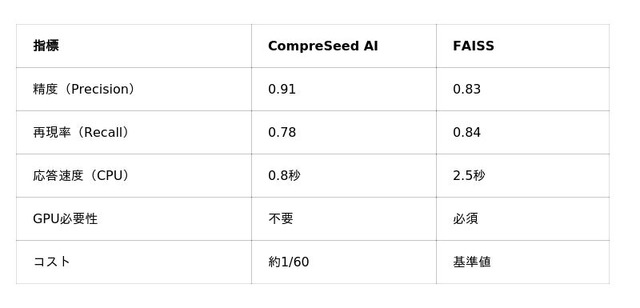
この結果から、CompreSeed AI は「汎用AI検索エンジン」としての実用水準に達しており、特にローカルAI・組み込みAI環境での利用価値が極めて高いことが確認された。
今後の展望
特許出願 : 同技術は関連する複数の特許出願準備が進行中です。
連携の推進 : 今後は学術機関・企業・自治体との連携を推進します。
省資源AI社会の実現 : 知的圧縮による省資源AI社会の実現を目指す計画です。
本件に関するお問い合わせは下記メールアドレスまでご連絡ください。
【連絡先】 info@xinse.jp
会社概要
アイテック(愛知県) 担当 玉木
創業 令和4年4月
事業内容 次世代AIの研究・開発
企業プレスリリース詳細へ
PRTIMESトップへ