









目の錯覚を利用!絵や文字に奥行きを与える投影技術「浮像(うくぞう)」
浮像は、プロジェクターから影を投影することで、絵や手書きの文字などに奥行きを与える光投影技術。これにより印刷された対象を浮き上がるように見せる、不透明な印刷物に透明な質感を持たせる、といったことが可能になる。実際にデモを見たが、思わず触りたくなるほどリアルで驚いた。
担当者によれば、様々な角度から投影できるとのことで、壁に貼られた印刷のポスターや、紙の商品パッケージの見せたい部分だけを強調することも可能。人の注目を集めたい、インパクトのあるメッセージを伝えたい、そんな場面で活用されそうだ。
音だけを聞いて情景を推定するAI
続いては、(カメラを使わずに)集音マイクだけを使って、まるでカメラで撮影したかのような情景を推定する技術。マイクアレイ(複数のマイク)で音を収録して、音を発している物体の種類、形状、動きなどをAI(人工知能)が予測している。担当者は「たとえば人は目をつぶっていても、喋っている人との距離感などを想像できます。それは経験で学んでいるから。この経験と知識をAIに与えています」と説明する。

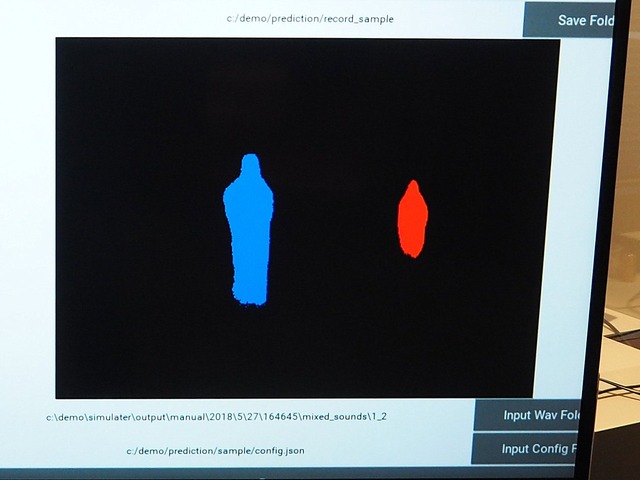
ブースでは2つのデモが紹介された。ひとつは、円形のレールの上を玩具の電車が走る空間に、マイクが4本挿入されたシチュエーション。担当者は「ここでAIは、どんな音がどの角度から飛んできているか情報を取得しつつ、ディープラーニングに基づいた予測を働かせています。この音は電車だ。この方向に、この速度で走っている。そうした予測から、モニターに走る電車の影を映しています」と説明する。
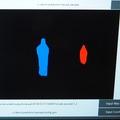
なるほどモニターでは、ほぼリアルタイムで青い影が円を描いて動いているのが確認できた。もうひとつは、これを人に応用したもの。カメラを置いていない部屋で男女2人が会話をしているシチュエーションで、AIは予測結果を画像として出力した。

将来的には、カメラの設置が好ましくないような生活環境や公共空間での見守り、防犯といった利用シーンを想定している。また、カメラとの組み合わせでセンシングの質を上げる、といった利用方法も考えられている。
聞きたい人の声に耳を傾けるコンピュータ
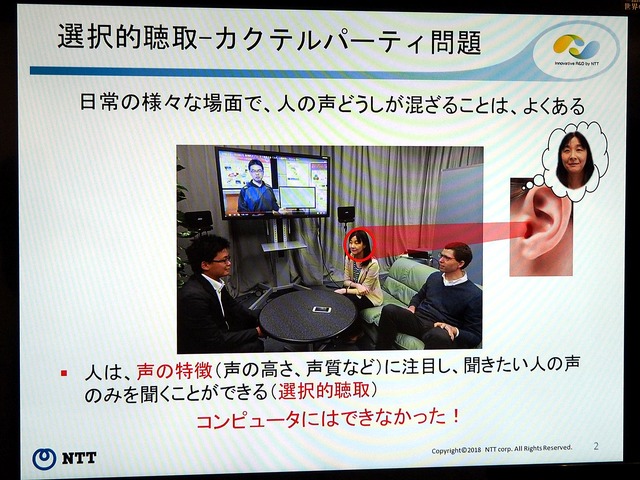
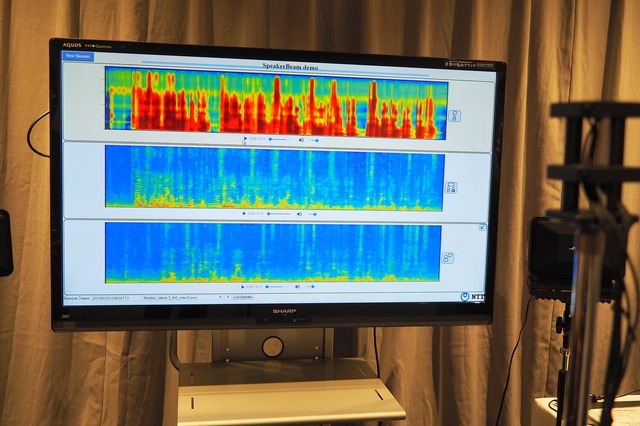
このほか興味深かったのは、複数の人の声が混ざった音声から、目的話者の声の特徴に基づき、その人の声だけを選択的に抽出する技術「SpeakBeam」。たとえ混雑するパーティ会場で録音した、複数人が同時に大声で喋っているような音源からでも、個人に切り分けて会話を抽出できる。
担当者は「カクテルパーティー効果、という言葉をご存知でしょうか。そもそも人間の脳に備わっている、選択的聴取能力です。人は声の高さ、声質などで聞きたい話者の声のみを聞いているわけですが、これをコンピュータで実現します」と説明する。

従来の技術でこれに近いことを実現するには、目的話者の音声データとして数時間ぶんの音源が必要となり、実用化にはほど遠かった。ところが人間の脳の仕組みを模したニューラルネットワークで機械学習を実施することで、10秒程度の音声データがあれば話者の声の特徴を抽出できるようになったという。
今後の展開として、担当者は「人の会話を理解する音声認識・ロボット技術に応用できます。また、聞きたい声だけを抽出できるボイスレコーダーや補聴器もつくれるでしょう」とアピールしていた。
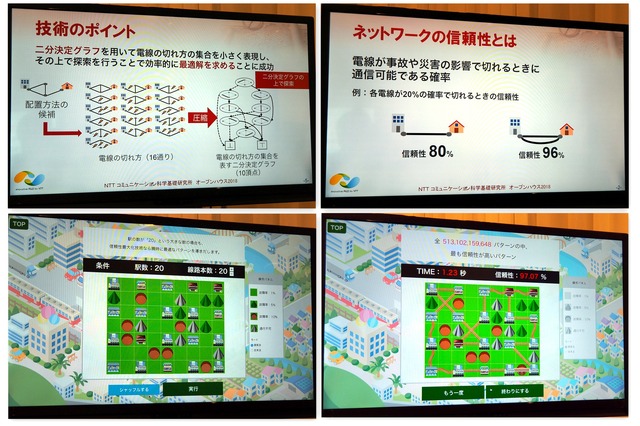
こわれにくい電線網や道路網をデザイン
電線や道路などを増強する場合に、最も信頼性が高くなるような増強方法を自動的に見つけることができる技術についても紹介された。既存の方法よりも信頼性の高いネットワークをより安価に設計できるようになる。今後は広域の道路網などの大規模なネットワークの設計や、自然災害による断線が発生するケースへの対応などをおこない、より幅広い場面で活用できる技術の実現を目指すという。