国会図書館、インターネット資料の収集を開始
ブロードバンド
ウェブ
-

コスパ最強の“手のひらサイズ”ミニPC「GT13 Pro 2025 Edition」「A5 2025 Edition」がGEEKOMから登場!
-

専用サイトでウイルス対策ソフトをテストするハッカーたち 〜 RSA調べ
-

BIGLOBE、SaaS型で「BIGLOBE IT資産管理サービス」を提供開始
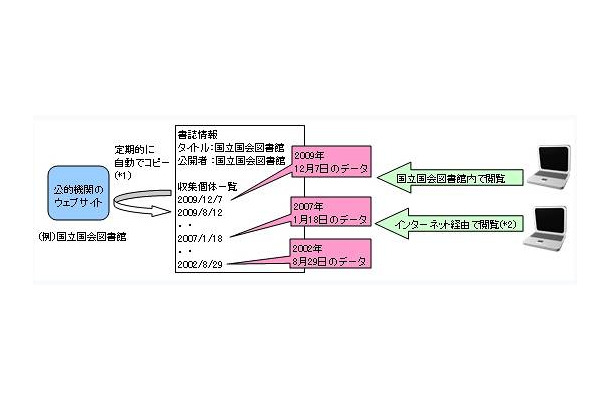

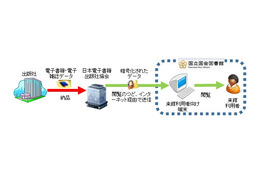
近年、公的機関(国、自治体、国公立大学など)の発行する報告書などの重要な資料が、紙媒体からWeb版へ移行しているが、紙資料を納本制度により保存するのと同様に、Webデータも収集・保存する必要があると考えられている。これを受け2009年7月に、国等の公的機関が発信するインターネット情報を国立国会図書館が収集し、保存することを可能とするため「国立国会図書館法」の一部が改正された。国会図書館では、2002年度より、国内発信のインターネット情報を対象に発信者から個別に許諾を得て、収集・保存・提供を行う「国立国会図書館インターネット情報選択的蓄積事業(WARP)」を実施していたが、この法改正にともない「国立国会図書館インターネット資料収集保存事業」と事業名を改称、新たに1日よりより広範な情報収集を開始する。
情報は、クローラー(自動収集プログラム)を用いてインターネット経由でWebサイトの収集を行い、Webサイト単位およびそこに含まれる著作物単位にデータを整理して同館システム内に整理・保存される。従来は情報発信機関との個別許諾契約に基づき収集していたが、今後は公的機関のものは許諾によらず、すべて収集・保存する。また、年1回だった頻度を月1回にするなど、収集頻度も増加させる。この事業で収集したWebサイトは国会図書館の施設内(東京本館、関西館)で閲覧可能。